Prompt-based learning has emerged as a successful paradigm in natural language processing, where
a single general-purpose language model can be instructed to perform any task specified by input
prompts. Yet task specification in robotics comes in various forms, such as imitating one-shot
demonstrations, following language instructions, and reaching visual goals. They are often
considered different tasks and tackled by specialized models. We show that a wide spectrum of
robot manipulation tasks can be expressed with multimodal prompts, interleaving textual
and visual tokens. Accordingly, we develop a new simulation benchmark that consists of thousands
of procedurally-generated tabletop tasks with multimodal prompts, 600K+ expert trajectories for
imitation learning, and a four-level evaluation protocol for systematic generalization. We
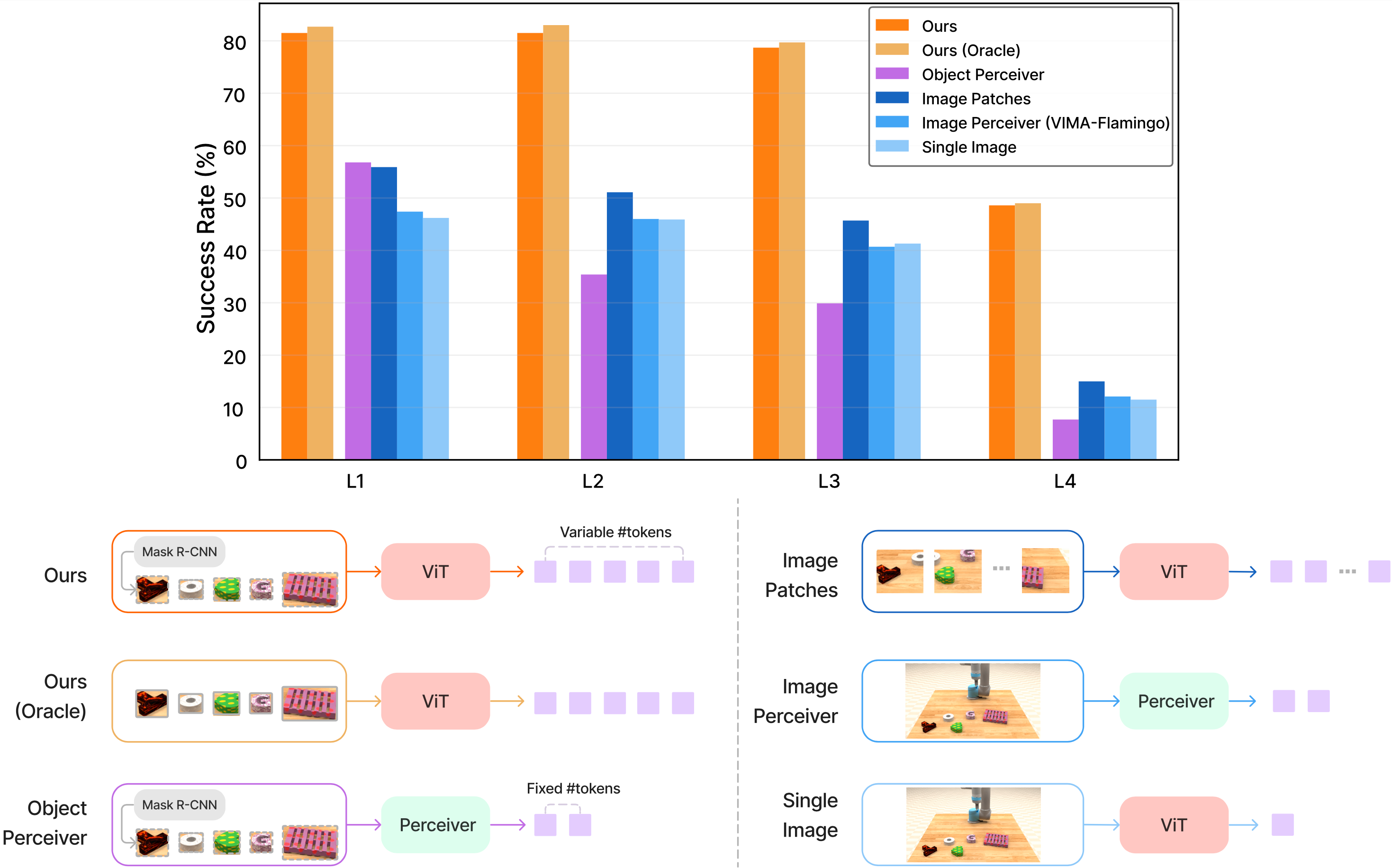
design a transformer-based robot agent, VIMA, that processes these prompts and outputs motor
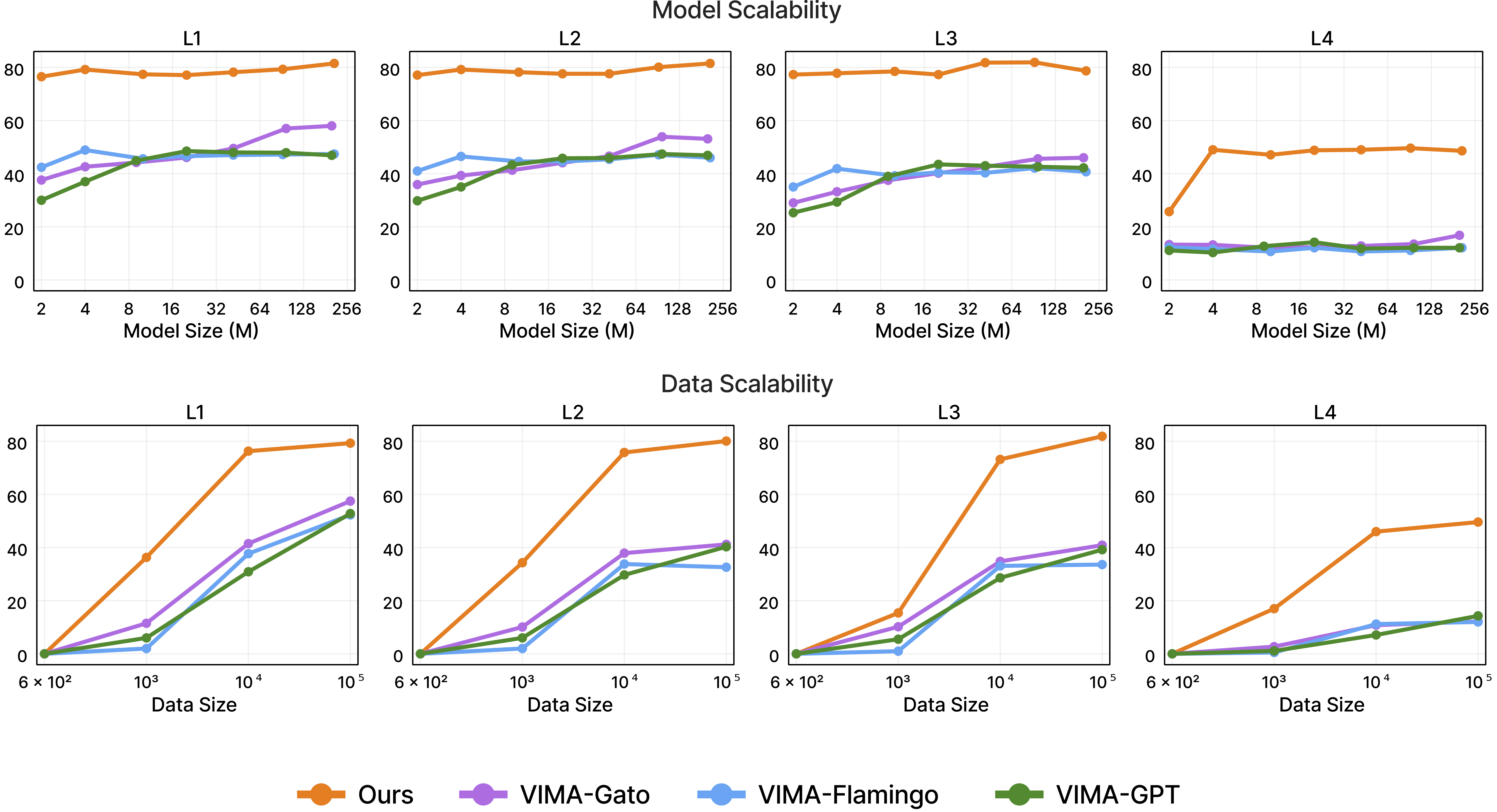
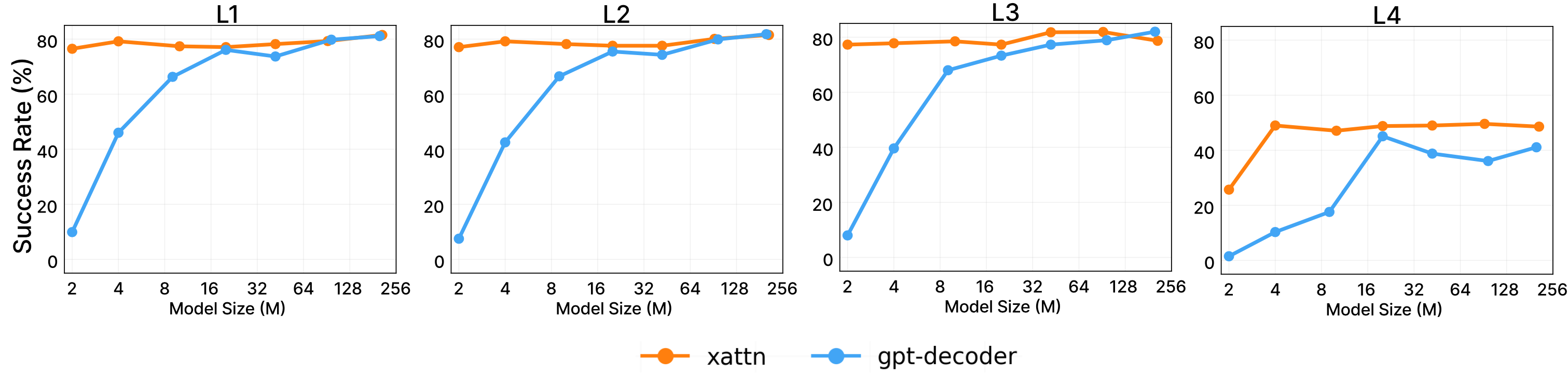
actions autoregressively. VIMA features a recipe that achieves strong model scalability and data
efficiency. It outperforms alternative designs in the hardest zero-shot generalization setting
by up to 2.9x task success rate given the same training data. With 10x less training data, VIMA
still performs 2.7x better than the best competing variant.